
In my journey of learning Machine Learning Algorithms, SVM is one of the most difficult algorithms to understand due to its complex mathematics behind it. So I decided to document my learning journey which can help the one which who need to learn this algorithm.
To learn the different variants of an algorithm I decided to follow the below plan of action and according to the plan of action, I will post the blog and also provide links.
Plan of Action:
Hard Margin SVM
Soft Margin SVM
SVM for non—linear data
SVM for Multiclass
SVR(Support Vector Regressor)
Support Vector Machines(SVM)
Support Vector Machines (SVM) is a powerful machine learning algorithm used for classification and regression tasks. It finds the optimal decision boundary that maximally separates different classes in the data.
SVMs can be used for a variety of tasks, such as text classification, image classification, spam detection, handwriting identification, gene expression analysis, face detection, and anomaly detection.
The main objective of the SVM is to find the optimal hyperplane that separates data points of different classes in the feature space as shown in the below figure. The hyperplane tries that the margin between the closest points of different classes should be as maximum as possible.

example (M1 and M2)
In the above example, consider the left graph for Model(M1) and the right graph for Model(M2). Imagine if we are trying to classify the given data point and which model is considered as the best model ( Let me know your answer through the comments sections — [M1 or M2] ).
It is clearly Model M2 is the best model because the margin between the support vectors is large as compared to Model M1 and we can easily classify the given data point without making mistakes.
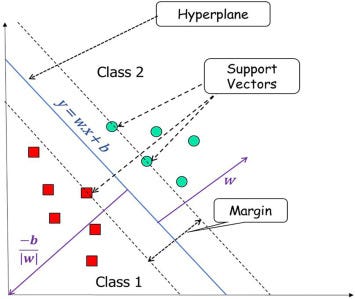
Support Vector Machine Terminology
Hyperplane: Hyperplane is the decision boundary that is used to separate the data points of different classes in a feature space. In the case of linear classifications, it will be a linear equation i.e. wx+b = 0.
Support Vectors: Support vectors are the closest data points to the hyperplane, which plays a critical role in deciding the hyperplane and margin.
Margin: Margin is the distance between the support vector and hyperplane. The main objective of the support vector machine algorithm is to maximize the margin. The wider margin indicates better classification performance.
Conclusion
In this blog, I just covered the basic terminologies of the SVM and how it works, and also going to cover the variants of the SVM in my upcoming blog as per the plan of action. So, I hope you enjoyed the explanation, and stay tuned for the upcoming blogs.