
"If you've designed a cockpit to fit the average pilot, you've actually designed it to fit no one" (Todd Rose, 2016)
In 2017, Merlo and colleagues published an excellent paper called "The tyranny of the averages and the indiscriminate use of risk factors in public health: The case of coronary heart disease" (1).
As of writing, this paper has only 48 citations according to google scholar. But I think it deserves far more exposure. Therefore, in this post, I will highlight and quote important points from the paper and also provide some comments.
Because of the obsession with lipids and LDL, I will use these "risk factors" or "risk markers" for illustration where appropriate.
Risk Factors and Prediction
Merlo and colleagues being:
Modern medicine is overwhelmed by a plethora of both traditional risk factors and novel biomarkers for diseases.
Indeed, we have a remarkable number of "risk factors" within the lipid world alone. These include total cholesterol, LDL cholesterol, HDL cholesterol, triglycerides, non-HDL cholesterol, apoB, small LDL particles, remnant cholesterol/lipoproteins, Lp(a), etc.
Epidemiologically, these factors are often assessed using summary statistics such as relative risks, odds ratios, and hazard ratios. But ultimately, we hope that any given risk factor would successfully distinguish between those individuals who will and will not get disease (i.e., predict disease):
We normally use simple measures of average association such as the relative risk (RR) or the odds ratio (OR). When using those measures, the implicit expectation is that of our capacity to accurately distinguish the individuals who will develop the disease from those who will not, improves in order for the provision of targeted preventive intervention.
For example, just because a group with a high level of a risk factor is three times as likely to get a specific disease than a group with a low level of the risk factor, does not mean that the risk factor can accurately predict who will and will not get the disease:
Therefore, from a clinical and even from a public health perspective, it is not enough to know the magnitude of the association between the exposure and the disease, what matters most is its DA [discriminatory accuracy], i.e., the capacity of the exposure to discriminate between individuals who will subsequently suffer a disease from those who will not.
This is an important issue, because the use of risk factors with poor discriminatory accuracy (low DA) could lead to problems such as unnecessary treatment and potential harm:
Promotion of screening and treatment of risk factors/biomarkers with a low DA may lead to unnecessary side effects and costs. The approach also raises ethical and political issues related to risk communication and the perils of both unwarranted medicalization and stigmatization of individuals with the risk factor/biomarker.
The Insufficiency of Risk Factors
Given the above concerns, Merlo and colleagues conducted a study assessing the discriminatory accuracy of various risk factors, based on a Swedish cohort with 18 years follow-up.
Although the results showed that risk factors were associated with coronary heart events, the discriminatory accuracy was poor, as seen in the following image for traditional risk factors:
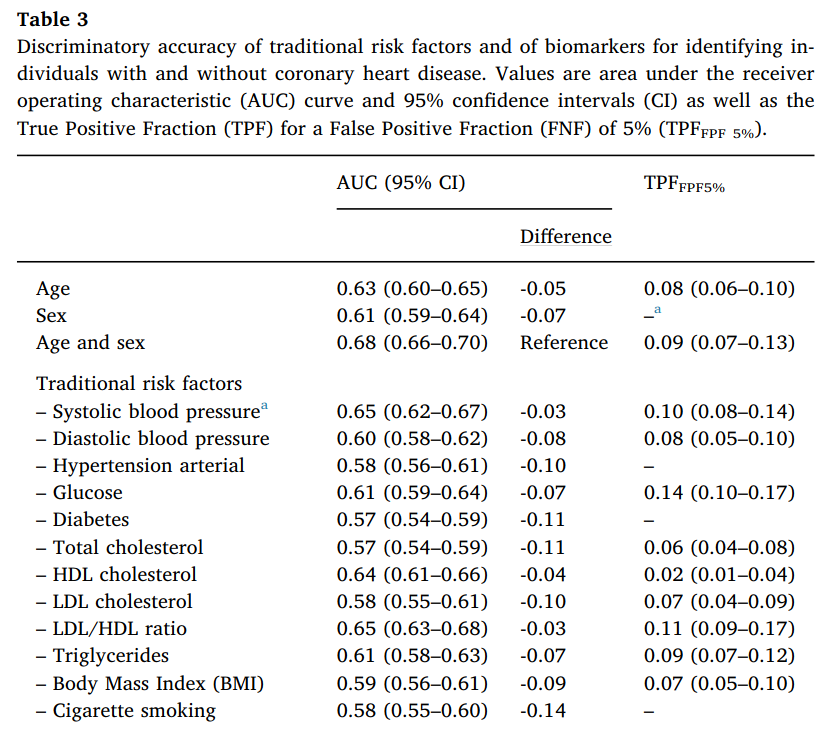
Thus, compared to age and sex combined, single traditional risk factors are generally no better and often worse predictors. Even in combination, traditional risk factors barely make a difference. And models with age and sex are only "slightly improved" by the inclusion of combined traditional risk factors.
In particular, note how exceedingly poor LDL cholesterol performs — hardly any better than flipping a coin (AUC = 0.58). Also, at a false positive fraction of 5%, LDL cholesterol would only identify 7% of those who would go on to have a heart event.
No wonder, then, that LDL cholesterol is called a "terrible" and "insufficient" predictor of risk (2,3).
While some researchers assert that we should use apoB instead of LDL cholesterol and lipid ratios, this would not improve matters. Lipid ratios sometimes have stronger relations with risk than apoB (see this post), and replacement of traditional lipids with apolipoproteins can actually worsen prediction (4):
Replacement of information on total cholesterol and HDL-C with apolipoprotein B and A-I significantly worsened risk discrimination (C-index change: −0.0028; P<.001) and risk classification (net reclassification improvement: −1.08%; P=.01).
To give another example: The FIELD trial found that the TC/HDL ratio was more strongly associated with cardiovascular risk than apoB and provided better discrimination (5). The AUC for apoB was only 0.545 — a useless predictor in this case.
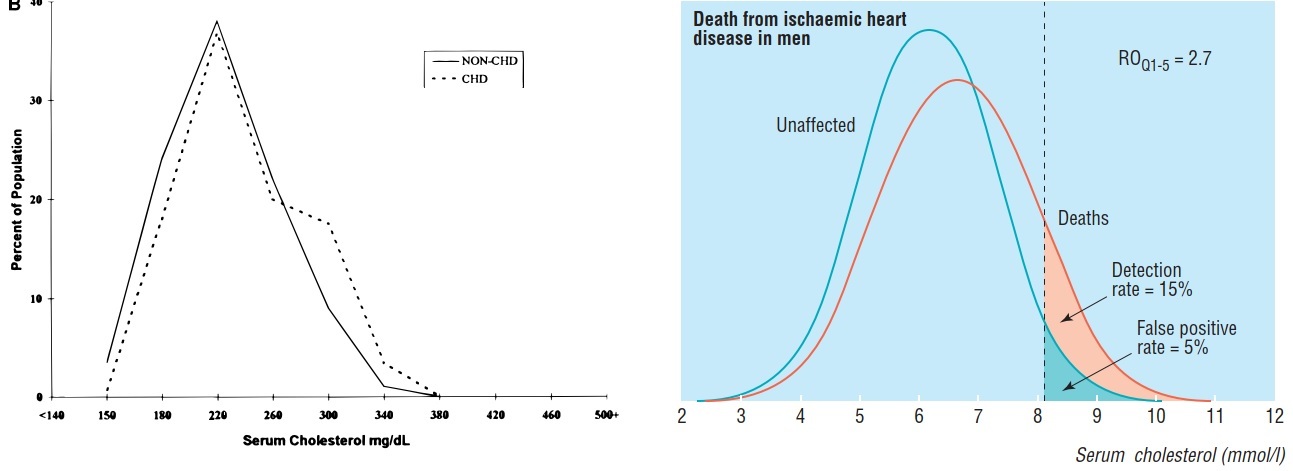
Overlapping Distributions
The above results imply a large overlap in the LDL distributions for those with and without CHD, which has been known for decades with total cholesterol:
 (Images taken from references 6 and 7)
(Images taken from references 6 and 7)
Note that the extremes of these distributions are unique. The extreme right of the distributions would include individuals with rare genetic lipid disorders, and the extreme left would include individuals dying prematurely from non-CHD causes.
Yet, despite the inappropriate inclusion of these extremes (6,8) and a host of confounding factors that cannot be adequately addressed by statistical methods, prediction for cholesterol is still remarkably poor.
As Stehbens noted of the overlapping distributions (6):
The gross overlap refutes assertions that CHD subjects have higher cholesterol values than controls, for most do not. Alleging otherwise is misrepresentation and an ecologic fallacy resulting from extrapolation from the mean to the individual.
We could also cite a mass of data where cholesterol or LDL had little to no association with cardiovascular events, cardiovascular mortality, and total mortality.
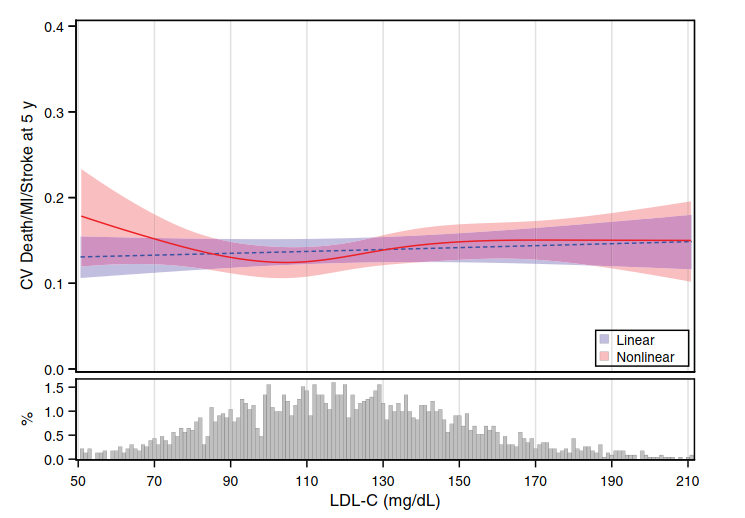 (Image: Sometimes, LDL has little to no association with cardiovascular events. Taken from reference 9. And we haven't even considered the endpoints of 'cardiovascular death' and 'all-cause mortality' where the performance of LDL is horrendous)
(Image: Sometimes, LDL has little to no association with cardiovascular events. Taken from reference 9. And we haven't even considered the endpoints of 'cardiovascular death' and 'all-cause mortality' where the performance of LDL is horrendous)
In these cases of no association, prediction for LDL would be useless. SPRINT, for instance, found no association between LDL cholesterol and cardiovascular events in the overall cohort. The AUC was 0.47 (10).
Not to mention the existence of publication bias that would "overemphasize the value of individual biomarkers and magnify estimates of the strength of the association" (11).
The point is: Prediction for LDL is likely worse than already acknowledged.
Therefore, when we see a study claiming that "almost half of patients hospitalized with CAD have admission LDL <100 mg/dL," we should not be surprised (12).
When we see a study claiming that 46% of all first events occur with LDL levels <130 mg/dL, we should not be surprised (13).
When it is claimed that "90% of the total cholesterol levels measured in people ≥30 years of age are useless by themselves as predictors of coronary disease," we should not be surprised (14).
And when we observe that many cardiovascular events still occur in those with LDL levels approaching zero, we should not be surprised (15,16).
Now back to Merlo and colleagues . . .
The Discussion Section
Based on their results, Merlo et al. state:
First, we confirmed a straightforward but scarcely discussed observation indicating that classical risk factors only provide a minor improvement to the DA [discriminatory accuracy] of a model including simple demographic characteristics, i.e., age and sex.
They then state the hard reality:
All over the world, there is a very strong conviction regarding the advantages of strategies of prevention against CHD based on the reduction of traditional modifiable risk factors such as high blood pressure (hypertension), high cholesterol, smoking, obesity, physical inactivity, diabetes, and unhealthy diets. However, we need to honestly confront the fact that, because of their low DA, none of those risk factors, alone or in any combination, provide an ideal ground for planning strategies of prevention in the general population.
And:
The fact that traditional cardiovascular risk factors have a low DA conveys consequences in regard to planning strategies of prevention in the general population. Non-pharmacological strategies of prevention directed towards life-style modification (for example, quitting smoking, increasing physical activity, eating healthy food, etc.) are normally safe and could be recommended to most people in the population even if the FPF [false positive fraction] is high. On the other hand, treatment of cardiovascular risk factors by pharmacological strategies of prevention (e.g., blood pressure lowering drugs, statins) does not appear to be suitable since treating false positive individuals may imply obvious problems of medicalization . . .
Of course, not all risk factors are the same. Unlike low LDL, for example, physical activity (especially when objectively measured) is consistently and strongly associated with reductions in mortality (17-19).
Nevertheless, given the poor predictive value of LDL, you would think its supposed causality would be questioned — or at least its degree of supposed causality. But instead, some researchers promote the "population strategy," where everyone needs to lower their risk factors by taking a polypill (a pill containing multiple drugs for different risk factors).
Apparently, we all have "abnormal" levels of risk factors. What we call "normal" is actually too high. Allegedly.
But Merlo and colleagues are not buying the polypill approach, stating:
Interestingly, in our study we actually arrived at the same conclusion as Wald et al. (1999), Wald and Law (2003) and Wald et al. (2011) concerning the minor incremental value added by traditional risk factors over and above age alone for discriminating future cases of cardiovascular disease. However, paradoxically, rather than questioning pharmacological preventive strategies against cardiovascular risk factors Wald and Law (2003), promote the “Polypill approach” . . . Our study shows, however, that this approach is flawed since it does not consider the DA of the risk factors. It does not matter that those risk factor are ‘causal’ on average. The Polypill approach is an extreme example, but it reflects how modern medicine in its most naïve form is falling towards a simplistic interpretation of human health based on pharmacological interventions targeting a few risk factors with low DA.
Continuing:
Several authors justify the low DA of a risk factor by distinguishing between ‘etiological’ and ‘screening’ perspectives (Wald et al., 1999) or between ‘association’ versus ‘classification’ (Pepe et al., 2004). For example, Wald et al. (Wald et al., 1999) stated that a high cholesterol concentration is a ‘strong risk factor’ for ischemic heart disease in ‘etiological terms’, even if the association is not sufficiently strong to be used as a basis for screening tests, since, in practice, its screening performance is poor . . . We do not agree. The distinction between ‘etiological’ and ‘screening’ or ‘association’ and ‘classification’ purposes bears an underlying contradiction.
Indeed, some authors admit that associations for cholesterol and apoB are "too low to be of much value in predicting disease" (20), but then attempt to get around this inconvenience by separating prediction from causation and association.
However, causation and prediction cannot be completely separated. Logically, if we knew the true causal circumstances, prediction would be accurate. Therefore, poor prediction implies ignorance of causation, as Merlo rightly noted (21):
In epidemiology, when measures of DA are low it indicates the lack of knowledge about causation mechanisms and the existence of gaps in our understanding of what truly drives health.
Moreover, associations do not give us any insight into the heterogeneity of responses to a risk factor (22):
Besides concerns on causal validity, measures of association do not inform on the individual heterogeneity of responses around the average and, thereby, provide insufficient information on the distribution of the health problem in the population, which is fundamental for planning appropriate public health intervention.
This brings us to an important point: Low discriminatory accuracy could simply mean that the "average effect of a risk factor is not generalizable to most individuals in the population" (1).
People are different in countless ways, and even if a risk factor is causal, we will not all respond to it in the same way:
It is possible to imagine a situation where a homogeneous exposure in a group causes a homogenous effect in all the individuals of the group. In this case, the exposure will have a DA of 100%. For instance, a blood pressure lowering drug may reduce diastolic blood pressure by 5 mmHg in each and every one of the individuals treated. However, this is not the case on most occasions. A possible reason for the low DA of many average associations is that average effects are a mixture of heterogeneous individual level effects (i.e., some individuals respond intensively to the exposure while others are resilient or might even respond in the opposite direction).
Importantly, it is not only observational epidemiology that is affected by the "tyranny of the means," but also randomized controlled trials (RCT):
The critique we directed in the previous section concerning the “tyranny of the means” also applies to the information provided by many RCT investigating the ACE [average causal effect] of a treatment. . . . It is a common clinical experience that the ACE obtained from a clinical trial does not seem to be reflected in the individual patient response to treatment. Nonetheless, this apparent conflict only reflects the fact that ACEs are just average measures . . . the results of a RCT provide very limited information for launching a treatment in the general population.
In fact, the 2021 polypill trial is a good example (23). After a mean follow-up of 4.6 years, the polypill had little effect on cardiovascular risk (ARR = 1.1%; P = 0.05), and there was little evidence of a mortality benefit (ARR = 0.5%; P = 0.37). This was the case despite a pre-randomization run-in period that may lead to exaggerated benefits and underestimated harms (24,25).
Thus, even a polypill that targets multiple "major risk factors" and also has pleiotropic effects (anti-inflammatory, etc.), may be futile for the vast majority of people and expose them to unnecessary harms.
Other Issues
Besides these points, Merlo et al. also question the population attributable fraction (PAF). This measure is the "share of the disease burden in a population that is attributable to a certain risk factor and, therefore, is potentially preventable. . . . assuming that the exposure is causal." (1)
They note, however, that the PAF gives "incomplete —if not misleading— information on the relevance of risk factors for planning strategies of prevention against CHD in the population."
Additionally, they argue against the "stochastic" concept of individual risk proposed by some epidemiologists. In the spirit of science (to discover and gain knowledge of causes), they opt for the more common sense deterministic approach:
It is more reasonable to think that the mechanism underlying an individual response might be very complex and difficult to determine so it might look like a stochastic phenomenon. However, rather than vindicating the ‘chance’ approach and an indiscriminate use of probabilistic estimations, we should recognize our current epistemological uncertainty (i.e., ignorance) and acknowledge that our lack of knowledge could be amended by a better understanding of individual responses.
Conclusion
In the end, Merlo and colleagues provide a much-needed critique of "risk factors." As they conclude:
We need a fundamental change in the way in which we currently interpret exposure categorizations in public health epidemiology for, if their DA is very low, what happens with the vast majority of recommendations given so far in epidemiology and public health? Are we misleading the community by creating alarm over risks that may be harmless for most individuals? Are we stigmatizing groups of people (e.g., people with mild hypertension) by blaming them for a bad ‘average’ health when, in fact, mild arterial hypertension cannot discriminate sick from healthy individuals? What are the ethical repercussions of using exposure categorizations with low DA? Are there problems of inefficiency, medicalization and stigmatization? Against this background, we not only need to urgently review new risk factors and biomarkers, but also classical and well-established risk factors as well as most other categorization being used in public health and (social) epidemiology.
References
1) Merlo, J., Mulinari, S., Wemrell, M., Subramanian, S. V., & Hedblad, B. (2017). The tyranny of the averages and the indiscriminate use of risk factors in public health: the case of coronary heart disease. SSM-population health, 3, 684-698.
2) Cuchel, M., Rohatgi, A., Sacks, F. M., & Guyton, J. R. (2018). JCL roundtable: High-density lipoprotein function and reverse cholesterol transport. Journal of clinical lipidology, 12(5), 1086-1094.
3) Tsaban, G. (2021). Low-density lipoprotein cholesterol and cardiovascular risk: a necessary causal agent but an insufficient predictor. European Journal of Preventive Cardiology.
4) Di Angelantonio, E., Gao, P., Pennells, L., Kaptoge, S., Caslake, M., Thompson, A., ... & Danesh, J. (2012). Lipid-related markers and cardiovascular disease prediction. JAMA, 307(23).
5) Taskinen, M. R., Barter, P. J., Ehnholm, C., Sullivan, D. R., Mann, K., Simes, J., ... & Keech, A. C. (2010). Ability of traditional lipid ratios and apolipoprotein ratios to predict cardiovascular risk in people with type 2 diabetes. Diabetologia, 53(9), 1846-1855.
6) Stehbens, W. E. (2001). Coronary heart disease, hypercholesterolemia, and atherosclerosis II. Misrepresented data. Experimental and molecular pathology, 70(2), 120-139.
7) Wald, N. J., Hackshaw, A. K., & Frost, C. (1999). When can a risk factor be used as a worthwhile screening test?. Bmj, 319(7224), 1562-1565.
8) Hamazaki, T., Okuyama, H., Ogushi, Y., & Hama, R. (2015). Towards a paradigm shift in cholesterol treatment. Ann Nutr Metab, 66(4), 1-116.
9) Nanna, M. G., Navar, A. M., Wojdyla, D., & Peterson, E. D. (2019). The Association Between Low‐Density Lipoprotein Cholesterol and Incident Atherosclerotic Cardiovascular Disease in Older Adults: Results From the National Institutes of Health Pooled Cohorts. Journal of the American Geriatrics Society, 67(12), 2560-2567.
10) Nguyen, L. S., Procopi, N., Salem, J. E., Squara, P., & Funck-Brentano, C. (2019). Relation between baseline LDL-cholesterol and cardiovascular outcomes in high cardiovascular risk hypertensive patients: A post-hoc SPRINT data analysis. International journal of cardiology, 286, 159-161.
11) Nissen, S. E. (2013). Biomarkers in Cardiovascular Medicine: The Shame of Publication Bias Comment on “Bias in Associations of Emerging Biomarkers With Cardiovascular Disease”. JAMA internal medicine, 173(8), 671-672.
12) Sachdeva, A., Cannon, C. P., Deedwania, P. C., LaBresh, K. A., Smith Jr, S. C., Dai, D., ... & Fonarow, G. C. (2009). Lipid levels in patients hospitalized with coronary artery disease: an analysis of 136,905 hospitalizations in Get With The Guidelines. American heart journal, 157(1), 111-117.
13) Ridker, P. M. (2003). High-sensitivity C-reactive protein and cardiovascular risk: rationale for screening and primary prevention. The American journal of cardiology, 92(4), 17-22.
14) Castelli, W. P. (1998). The new pathophysiology of coronary artery disease. The American journal of cardiology, 82(10), 60-65.
15) Juan Vicente-Valor, Xandra García-González, Sara Ibáñez-García, María Esther Durán-García, Ana de Lorenzo-Pinto, Carmen Rodríguez-González, Irene Méndez-Fernández, Juan Carlos Percovich-Hualpa, Ana Herranz-Alonso, María Sanjurjo-Sáez, PCSK9 inhibitors revisited: Effectiveness and safety of PCSK9 inhibitors in a real-life Spanish cohort.
16) Bornfeldt, K. E., Linton, M. F., Fisher, E. A., & Guyton, J. R. (2021). JCL roundtable: Lipids and inflammation in atherosclerosis. Journal of Clinical Lipidology, 15(1), 3-17.
17) Ramakrishnan, R., He, J. R., Ponsonby, A. L., Woodward, M., Rahimi, K., Blair, S. N., & Dwyer, T. (2021). Objectively measured physical activity and all cause mortality: a systematic review and meta-analysis. Preventive Medicine, 143, 106356.
18) Acevedo, M., Valentino, G., Bustamante, M. J., Orellana, L., Adasme, M., Baraona, F., ... & Navarrete, C. (2020). Cardiorespiratory fitness improves prediction of mortality of standard cardiovascular risk scores in a Latino population. Clinical Cardiology, 43(10), 1167-1174.
19) Argyridou, S., Zaccardi, F., Davies, M. J., Khunti, K., & Yates, T. (2020). Walking pace improves all-cause and cardiovascular mortality risk prediction: A UK Biobank prognostic study. European journal of preventive cardiology, 27(10), 1036-1044.
20) Wald, N. J., & Morris, J. K. (2011). Assessing risk factors as potential screening tests: a simple assessment tool. Archives of internal medicine, 171(4), 286-291.
21) Merlo, J. (2018). Multilevel analysis of individual heterogeneity and discriminatory accuracy (MAIHDA) within an intersectional framework. Social Science & Medicine, 203, 74-80.
22) Merlo, J., & Mulinari, S. (2015). Measures of discriminatory accuracy and categorizations in public health: a response to Allan Krasnik’s editorial. The European Journal of Public Health, 25(6), 910-910.
23) Yusuf, S., Joseph, P., Dans, A., Gao, P., Teo, K., Xavier, D., ... & Pais, P. (2021). Polypill with or without aspirin in persons without cardiovascular disease. New England Journal of Medicine, 384(3), 216-228.
24) https://www.ge-bu.nl/en/article/primary-prevention-using-a-polypill?full
25) Khalili, D., Hadaegh, F., Pirzadeh, M., & Azizi, F. (2021). Polypill's cardiovascular and non-cardiovascular mortalities. Journal of Diabetes & Metabolic Disorders, 20(2), 2133-2134.